Background and historical origins
This chapter provides a summary of the main technical principles around GenAI, including some historical background. GenAI is currently defined more in a descriptive manner than by precise technical features. The Organisation for Economic Co-operation and Development (OECD) defines GenAI as "a technology that can create content, including text, images, audio, or video, when prompted by a user" (Lorenz et al. 2023). "Prompts" here correspond to textual instructions, usually produced by the human users, optionally combined with some given data. Although not mentioned, it is expected that the generated content is new, meaningful and human-like.
In the recent AI Act, the European Union defines GenAI as a type of foundation model (European Commission, European Parliament 2023). Foundation models correspond to general purpose AI models trained on large and diverse datasets in order to be used more easily for many different tasks. GenAI systems are a specific subset of foundation models "specifically intended to generate, with varying levels of autonomy, content such as complex text, images, audio or video." This definition emphasizes that new content is generated based on existing large training datasets, raising various issues and biases more particularly addressed by the AI Act.
From the point of view of general users, one key aspect is that unlike the traditional "supervised" machine learning models, which require a large amount of task-specific annotated training data, these models can generate new content just by writing natural language prompts. Therefore, using GenAI tools based on these models does not require technical skills. For the first time, modern cutting-edge AI becomes directly accessible to the general public.
This accessibility has made possible a widespread diffusion of GenAI tools in the last two years. For example, in 2022, models like Stable Diffusion (Rombach et al. 2021) and Midjourney (Midjourney 2022) have attracted a lot of attention on social media and democratized GenAI in popular culture (Midjourney 2022). ChatGPT for conversational systems became the fastest product to attain 100 million users (OpenAI 2022). On the professional side, GitHub Copilot (GitHub 2021) has anchored GenAI in software development: 92% of US-based developers are already using AI coding tools according to a recent GitHub survey (GitHub 2023b).
The developments that led to GenAI have been a long and steady progress in the field of machine learning and neural networks. Amari-Hopfield Network (Amari 1972, Hopfield 1982), a type of neural network with associative memory, and Long Short Term Memory (LSTM) recurrent neural networks (Hochreiter and Schmidhuber 1997), are often mentioned as early foundations for the development of GenAI. The Amari-Hopfield Network demonstrated how networks could store and retrieve patterns, resembling human memory processes. LSTM recurrent neural networks expanded on this by introducing a mechanism to capture and learn complex sequential patterns, overcoming the limitations of traditional recurrent networks in handling long-range dependencies.
Early effective GenAI was however not based on neural networks, but on probabilistic graphical models such as Markov networks, which learn transitions over states in graph-based representations rather than using bio-inspired structures. These statistical language models had already led to practical commercial applications in the 1990s.
Language models aim at predicting a next "token," for example a word, given a sequence of observed tokens. Applied iteratively, it is possible to generate text or speech that mimics human language. This iterative method for generating sequences, like a sequence of words, is characteristic of so-called autoregressive models and can be viewed as an auto-completion function. Successful early applications include machine translation, such as Google statistical machine translations deployed in the 2000s, as well as speech and text generation.
Deep learning
In the 2010s, neural networks became the dominant approach in AI with deep learning. Although neural networks are well known since the 1950s (Rosenblatt 1957), these models could only use a very limited number of neurons and layers – such as the so-called multilayer perceptron (MLP) – until the 1990s. Deep learning is the result of 30 years of cumulative progress to increase ("deepen") the number of layers of neural networks.
With traditional machine learning techniques, the performance can quickly reach a plateau as the amount of training data increases. Adding more data thus becomes useless after a while. One of the key properties of deep learning is that the performance continuously increases with the increase in training data. In other words, the more data we feed to a deep neural network (DNN), the better the deep neural network generally performs. The performance of these models becomes conditioned by the capacity of the computers and the amount of data used for training. Deep learning can surpass any other machine learning approaches, as long massive data and computing resources are available.
One of the main findings of the WIPO Technology Trends on Artificial Intelligence was that deep learning was by far the biggest and fastest growing technique in AI at the end of the 2010s, both for patents and non-patent literature (WIPO 2019). The progress in deep learning led to breakthrough results in so-called generative tasks.
Discriminative versus generative tasks
Deep neural networks can usually be adapted to two different kinds of tasks:
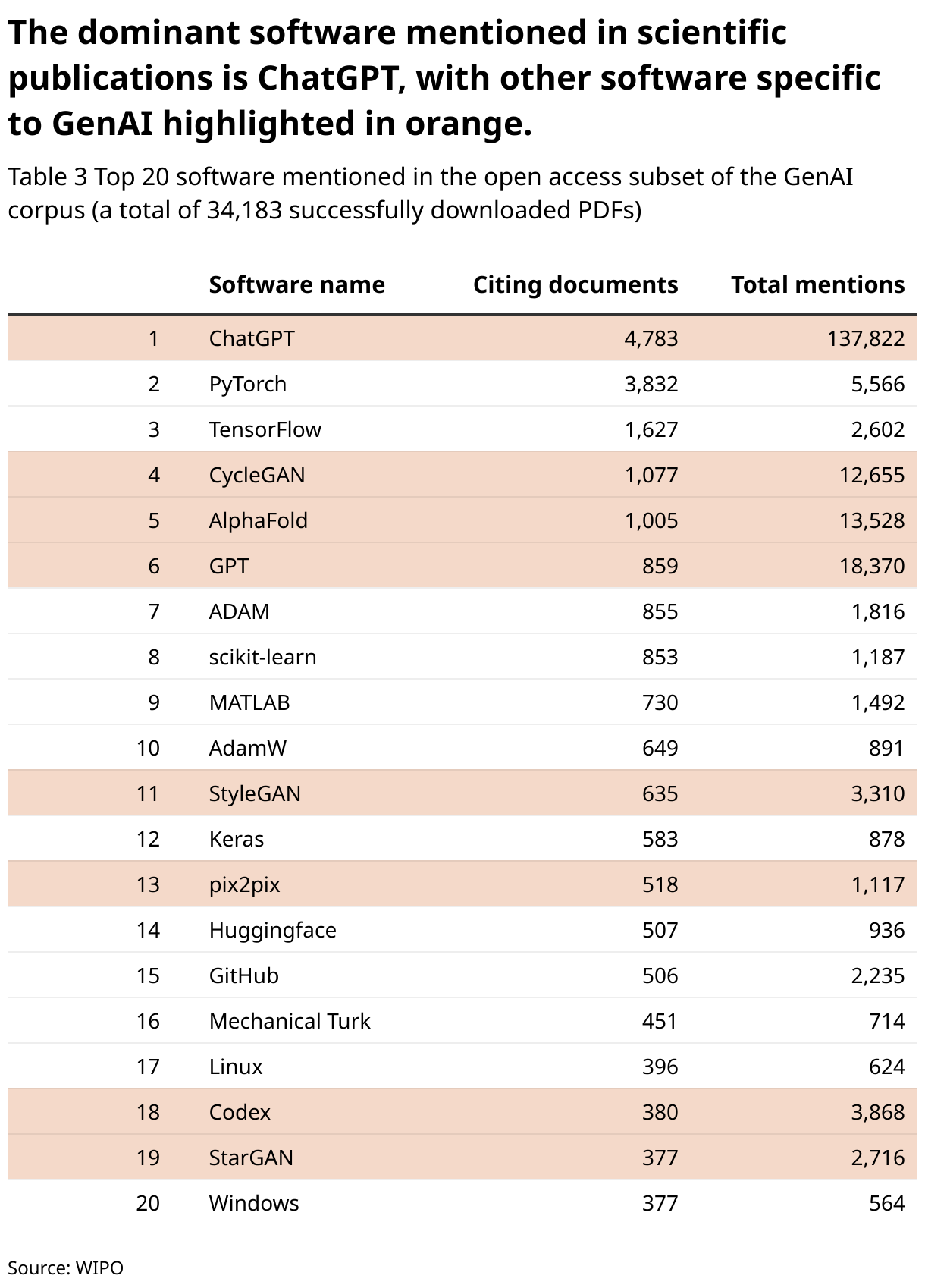
Discriminative tasks involve a decision on the input data, such as classification, identifying names in texts or segmenting an image. Discriminative models are models adapted and trained to separate input data into these different classes.
Generative tasks involve the creation of new data samples given some input data. Generative models are models adapted and trained to create such new data. They are typically used to translate text, generate images, summarize text or answer questions.
Figures 2 and 3 illustrate these fundamental types of machine learning tasks. Discriminative models excel in classification but cannot generate new data. In contrast, generative models can also address discriminative tasks, but with lower accuracy than discriminative models. Generative models have more parameters, are computationally more expensive and often require more training data than discriminative models.

What GenAI models exist?
With its ability to represent and learn complex data patterns and to scale them, deep learning appeared very well-fitted for data generation, but also for modeling different types of data. In recent years, it has enabled the development of various types of GenAI models. Among the most significant are generative adversarial networks (GANs), decoder-based large language models (LLMs), variational autoencoders (VAE), and diffusion models.
Generative adversarial network
A generative adversarial network (GAN) is a deep learning model for task generation introduced in 2014 by Goodfellow et al. (2014). A GAN consists of two parts, a generator and a discriminator. The generator is a neural network generating output images and the discriminator a neural network evaluating how realistic the image generated by the generator is. The generation process is then a competition between these two parts. The generator tries to improve its output to mislead the discriminator and the discriminator tries to improve its ability to distinguish real images from generated ones, to avoid being misled by the generator. As a result, the generator will maximize its capacity to generate realistic images. GANs are used today for many tasks involving images such as generation and enhancement of photorealistic images.
Large Language Models
Large Language Models (LLMs) are the basis of modern conversational systems (chatbots) such as ChatGPT or Bard. These models are trained on large datasets to learn the patterns and structures within the data, enabling them to generate new content that is coherent and contextually relevant. LLMs in GenAI focus specifically on generating human-like text by predicting the next statistically most likely word and are used for various natural language processing tasks, including text completion, language translation, summarization and more. The training process of LLMs involves pre-training on a large corpus of text data, allowing the model to learn the statistical properties and linguistic nuances of the language. To achieve this, most of the LLMs use transformers, a type of neural network architecture designed specifically for natural language processing (NLP) tasks, that were introduced first in 2017 (Vaswani et al. 2017). Transformers have allowed researchers to train increasingly large models without having to label all the data beforehand. They are based on the idea of self-attention, which means they can focus on different parts of the text simultaneously. This allows them to capture long-range dependencies in text, which is important for understanding and phrasing complex language. As a result, LLM-based chatbots are able to generate text that is coherent and contextually relevant.
Once trained, the models can be fine-tuned for specific tasks or used directly to generate diverse and contextually appropriate text. Recently, multimodal large language models (MLLMs) have been gradually taking the lead from traditional LLMs. MLLMs are overcoming the limitation of purely text-based input and can access knowledge from multiple modalities – and can thus interact more fully with the real world.
(Variational) Auto-encoder
An auto-encoder model is based on three parts: encoder, code and decoder. The encoder is a neural network that learns how to encode and compress input data into an intermediary representation, the code, which is basically a sequence of numbers. The code is then used by the decoder, another neural network, which has learnt how to decompress and reconstruct data into the expected input format. Beyond data compression, the objective of the autoencoders is to learn how to represent the nature of some data, so that a small modification of this internal representation can still be re-constructed into a new meaningful output. Autoencoders are common in GenAI today. A large number of variants have introduced multiple improvements, such as the popular variational autoencoders (VAEs), published in 2013 (Kingma and Welling 2013), and used for generating sophisticated and diverse image samples.
The original transformer model (Vaswani et al. 2017) is also an encoder-decoder architecture. It has been adapted for creating large language models used for text generation by keeping only the decoder part in the case of the OpenAI GPT model family. In other terms, modern LLMs are decoder-based large language models.
Autoregressive models
Autoregressive models are a class of probabilistic models that describe the probability distribution of a sequence of observations by modeling the conditional probability of each observation given the previous observations in the sequence. In other words, autoregressive models predict the next value in a sequence by considering the previous values.
In the context of GenAI, autoregressive models are often used to generate new data samples.
A model is trained on a dataset, which is then used to generate new data points by predicting one element at a time, based on the previously generated elements. This makes autoregressive models suitable for tasks such as language generation, image synthesis and other generative tasks. Examples of autoregressive models in GenAI include autoregressive moving average (ARMA) models, autoregressive integrated moving average (ARIMA) models and PixelCNN for image generation. Autoregressive models have been particularly successful when applied to natural language processing tasks (e.g. most modern LLMs, such as GPT-3 or GPT-4 are autoregressive) and image generation tasks, such as PixelCNN.
Diffusion model
Diffusion models are inspired from the concept of diffusion, which is used in physics to model the movement of a set of particles in two different physical areas. A diffusion model for image generation involves a neural network to predict and remove noise in a given noisy image. The generation process is equivalent to first applying random noise (random pixels) to an image and then iteratively using the neural network to remove the noise. As the noise is progressively removed, a novel and meaningful image is constructed, controlled by additional machine learning mechanisms, as illustrated by Figure 4. Diffusion models have made considerable progress in recent years and are now very successful for text-to-image generations, such as the Stable Diffusion (Rombach et al. 2021) and the DALL-E model families (OpenAI 2021).

What are GenAI modes?
Generative AI models are very effective for a variety of applications, to a point where they can challenge some aspects of human creativity. Mature models support different types of input and output data (modes) and are not limited to text and images, making GenAI relevant potentially to many economic areas.
Image, video
One data type for GenAI is images and videos. Generative models can typically translate an image to another image, enhancing or modifying the style of the input image. To learn the patterns and relationships between pixels, GenAI models are trained on large datasets of images and videos, but also combined with text. For example, diffusion models can produce impressive high-resolution images from short textual description, as illustrated by Stable Diffusion, released in 2022 (Rombach et al. 2021). In another way, models such as OpenAI’s CLIP (Contrastive Language-Image Pre-training) in 2021 (Radford et al. 2021) or the larger DeepMind’s Flamingo in 2022 (Alayrac et al. 2022) are used to generate, for instance, captions from an image or from videos. Figure 5 further illustrates Flamingo’s ability to analyze an image following a text prompt in the form of a question.

Text
The releases of the GPT (Generative Pre-Trained) model by OpenAI in 2018 (OpenAI 2018) and more significantly of GPT-2 in 2019 (OpenAI 2019) have accelerated the development of GenAI. These LLMs rely on text as the main data mode. The core technique of the current text-based approaches is to use the deep learning architecture called transformer (Vaswani et al. 2017), mentioned previously, which has the ability to maintain learning capacities from a large amount of unlabeled text, scaling to billions of parameters as the number of layers in the model increases. This sort of model can address a large variety of tasks, such as automatic summarization, machine translation, essay generation, paraphrasing or writing style enhancement, in a reliable manner.
In November 2022, ChatGPT demonstrated the new capacity of LLM-based chatbots to the broad public (OpenAI 2022). Text-based LLMs learn from extremely large amounts of texts, in the range of several hundred billions of tokens. As they maintain learning capacity, they not only learn the general language, but also how to generate text about a variety of facts concerning entities and events in the world. ChatGPT exploits this property by further training an LLM with successive prompts and replies validated by human trainers. The LLM is thus further trained (fine-tuned) for a conversational use, enabling fluent and versatile dialogs on top of the existing capacity to generate human language texts. Users can initiate any sort of conversation with the system, which responds in a human-like manner, including follow-up queries and reformulations, and factual information, in a much more convincing manner than the usual chatbots.
Since then a large number of competing products have appeared, including techniques to better control the reliability of the communicated information and to refine the dialogs. In particular, retrieval augmented generation (RAG) is a technique widely used, which restricts the provided information with the results of preliminary requests to one or several search engines. More costly, additional fine-tuning is another way of modifying the LLM itself for further specializing or improving the choice of replies.
Speech, sound, music
In 2016, DeepMind introduced WaveNet, a deep neural network able to generate audio waveforms (van den Oord et al. 2016). WaveNet was a milestone in generative models for realistic human speech, but more generally for any kind of audio. Previous text-to-speech systems were mostly based on concatenating relatively large sound fragments, like phonemes, together to form words and sentences. This approach requires a very high number of voice recordings from the same speaker, with often unnatural tone and cadence. WaveNet, on the contrary, learns how waveforms change over time at a very low level, recreating the sound of speech one sample at the time, with 16,000 samples generated per second. In addition to more natural sounding voices, only a few minutes of real-life recordings are required to mimic one particular voice. The same generative approach can be used for other forms of audio, like music. Trained on 280,000 hours of music by Google researchers, MusicML is a recent example of such a generative system producing entire songs from text prompts (Agostinelli et al. 2023).
Code
In 2021, GitHub, the main open-source software platform, and OpenAI released a programming assistant for developers called Copilot (GitHub 2021), based on a modified version of GPT-3. The LLM is trained on English language and on a massive amount of public software code repositories that the GitHub company hosts.
The assistant can perform code generation based on some natural language describing a programming problem. It can provide code completion, for example as real-time suggestions in integrated development environments. It has also the ability to comment and explain existing or generated code. Such a tool illustrates that GenAI has the potential to change the working methods of many professions, with the prospect of productivity gains.
Molecules, genes, proteins
Some GenAI models are trained on large datasets of chemical molecules, genes and proteins. This enables them to generate new chemical molecules, genes and proteins structures with desired properties. GenAI models can also be used to design new drugs and therapies, and to improve the efficiency of chemical and biological processes. In 2021, DeepMind’s AlphaFold 2 system won the CASP14 competition on predicting protein structures based on a transformer model (Jumper et al. 2021). Knowing the stable 3D structure of a protein is necessary to understand its biological function. The "protein folding problem" is however very challenging. We only know the structures of about 170,000 proteins based on decades of experiments, out of an estimated over 200 million existing proteins across all life forms. At the CASP competition, the accuracy of AlphaFold 2 was comparable to existing experimental techniques. Generating automatically reliable protein structures is a key scientific milestone, and this result has promising implications for drug discovery.
3D image models
Less-known applications of GenAI relate to the ability to reconstruct a 3D scene from incomplete input, for example a few 2D images. Introduced in 2020, Neural Radiance Field (NeRF) is a fast deep learning method, enabling the geometric modeling of a scene, as well as a photorealistic rendering of novel views (Mildenhall et al. 2020). This GenAI technique has already reached the general public. Progressively deployed for certain cities in 2023, Google Immersive View uses NeRF to transform 2D street pictures into 3D representations (Tong 2023), see Figure 6. Applied to medical imaging, it allows, for example, the generation of 3D computerized tomography (CT) scans from a few or a single-view X-ray, reducing the exposure to ionizing radiation. In robotics, these techniques can help robots interact with their environment, with improved perception of transparent and reflexive objects (Corona-Figueroa et al. 2022). Other applications include surface reconstruction from satellite imagery or photorealistic content creation in product design or augmented reality.

Synthetic data is annotated information that computer simulations or algorithms generate as an alternative to real-world data. It usually seeks to reproduce the characteristics and properties of existing data or to produce data based on existing knowledge (Deng 2023). It can take the form of all different types of real-world data. For example, synthetic data can be used to generate realistic images of objects or scenes to train autonomous vehicles. This helps for tasks like object detection and image classification. Because of synthetic data, millions of diverse scenarios can be created and tested quickly, overcoming limitations of physical testing.
In general, synthetic data is very useful for training AI models when data do not exist, or are incomplete or not accurate enough. The development of synthetic data is possible through a process called label-efficient learning. Labeling data is an important step in training many AI models. Traditionally, labeling data involved humans who annotate data with the desired information, which is a time-consuming and expensive process, especially for large datasets. GenAI models can reduce the cost of labeling, either by creating realistic synthetic data (images, text, etc.) with desired labels, by augmenting existing training data by generating additional labeled data points, or by learning an internal representation of the data that makes it easier to train AI models with less labeled data.
The research company Gartner expects synthetic data to become the dominant data type in GenAI by 2030 given its many advantages (Ramos and Subramanyam 2021), see Figure 7. Synthetic data allows for a rapid development of GenAI models by avoiding lengthy procedures for data acquisition.
The increasing availability of data has been a major factor in the development of GenAI. Many datasets have been developed and assembled for GenAI purposes. However, it is complicated to track the activity related to data, because of the high fragmentation of platforms and services related to public datasets. As of November 2023, Re3data, a worldwide registry of research data repositories, reports 3,160 different research dataset repositories in the world (Re3data 2023). Most of the data available via these platforms are distributed in open access, often under Creative Commons licenses, and come from various public institutions: research institutions, public administrations, museums, archives, etc. In addition, raw data such as large-scale web page scraping (the copy and harvesting of public web pages as rendered on web browsers) are commonly used.
The actual training data used by GenAI models is currently poorly documented. We rely on a text mining analysis of the open access subset of the GenAI corpus (34,183 articles out of a total of 75,870) to capture the actual used datasets. With this approach, we obtained a total of 978,297 dataset mentions (see Appendix A.1 for the methodology).
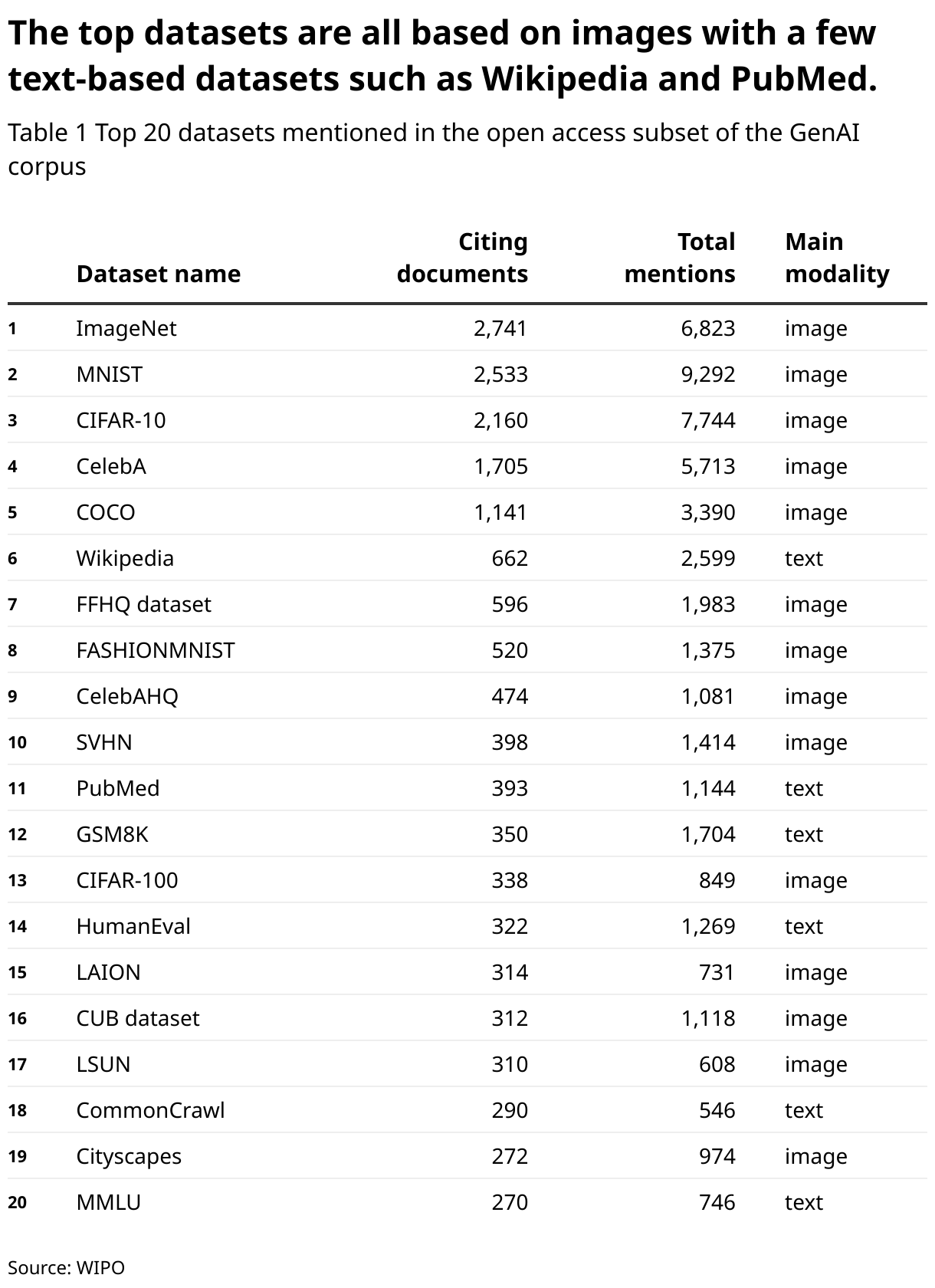
Table 1 shows that the most cited datasets appear to be image understanding datasets, such as ImageNet, MNIST, CIFAR, etc. They are commonly used in training and evaluating GenAI models, particularly GAN models. The first text-based datasets are Wikipedia and PubMed. HumanEval is the first dataset specific to text and LLM: It is an evaluation benchmark for code generation systems like GitHub Copilot (GitHub 2021).
The two main data sources to train GenAI models from scratch are LAION (position 15) and Common Crawl (position 18). Common Crawl is a non-profit organization that crawls the web and provides its datasets freely to the public (Common Crawl 2023). Their datasets include copyrighted works that are distributed from the US under fair use claims, in the form of samples of websites. Most LLMs use Common Crawl data for training.
LAION, Large-scale Artificial Intelligence Open Network, is a non-profit organization providing large datasets related to images (image-text pairs) (LAION 2023). These datasets are behind most GenAI text-to-image models like Stable Diffusion. To mitigate copyright and GDPR issues, the datasets do not include images, but URLs (web addresses) referencing the images.
Proprietary versus open models
GenAI is bound to have a significant impact on many industries as a technological enabler for content creation and productivity improvement. To enable the practical usage of GenAI, two types of models are emerging, proprietary models and freely available open models:
The first category includes OpenAI’s GPT3 and 4 or Alphabet/Google’s BARD chatbots. The companies behind these models allow developers and individuals to access their API for a fee. These models come with professional support, documentation, and large computing infrastructure, ensuring a high level of reliability and performance.
Open models, usually called open data or open-source models, are made available to the public for free, and anyone can use, modify and distribute them, possibly with some restrictions (e.g. for commercial applications). Open models benefit from a community of developers, researchers and users as well as from transparency, since the code for running the model is usually available for scrutiny. Examples of open model are Meta’s LLaMA 2 and 3 and Mistral AI series of models. However, today only a small number of models such as GPT-NeoX (EleutherAI) and OLMo (Allen Institute for AI) can be considered as fully open, releasing both model and training data, and the code for training and running the model, without usage restriction.
Availability of open access GenAI models
The Hugging Face commercial platform is currently the most popular and well-known service for sharing open access machine learning models publicly (Hugging Face 2023), without limitation to data and model types. At the time of this report, there is no comparable alternative in terms of number and versatility of shared models.
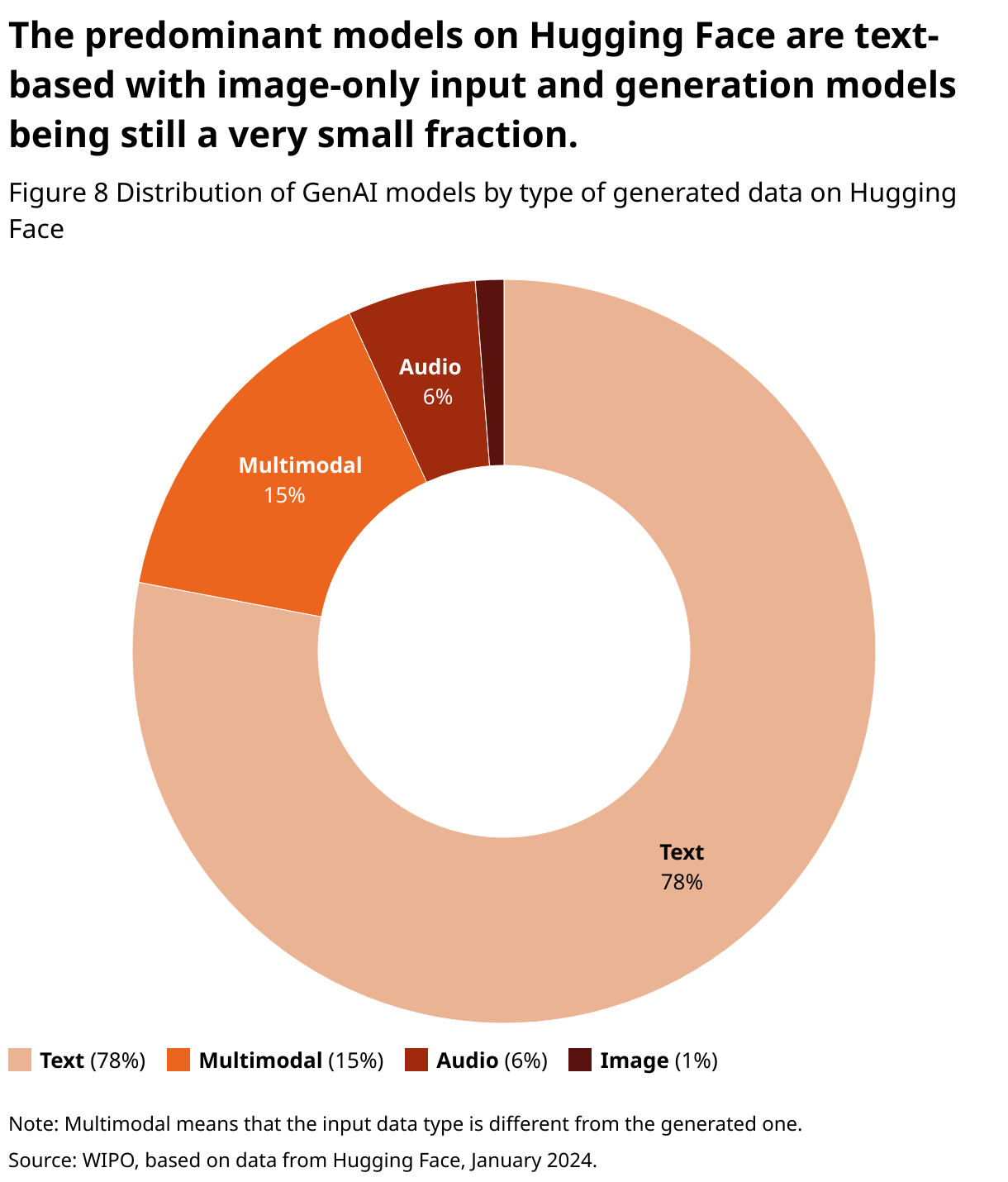
As of January 20, 2024, Hugging Face hosts 477,329 machine learning models of which 106,430 (22.3%) can be considered as GenAI models. It is possible to break down the different models in terms of the type of input and generated data (see also the following chapter for more information about data types). Figure 8 shows that text generative models are largely dominant, likely related to the rise of conversational systems in the last two years. Most of the image-based models appear multimodal, using textual prompts as input or generating image captions, rather than performing image-to-image generation.
GenAI software
The production of software is hard to track because of the multiplication of software publication channels, the variety of development environments, the distributed nature of modern software engineering and the absence of a central metadata index. However, the main open-source development platform GitHub offers a good proxy for capturing a large spectrum of activity in a single place. With a reported number of 284 million public repositories, it is the reference for open-source collaborative development (GitHub 2023c). When core technical innovations are made available very early as open-source software and open access models, large organizations can benefit from this with limited risks and investment compared to direct internal research.
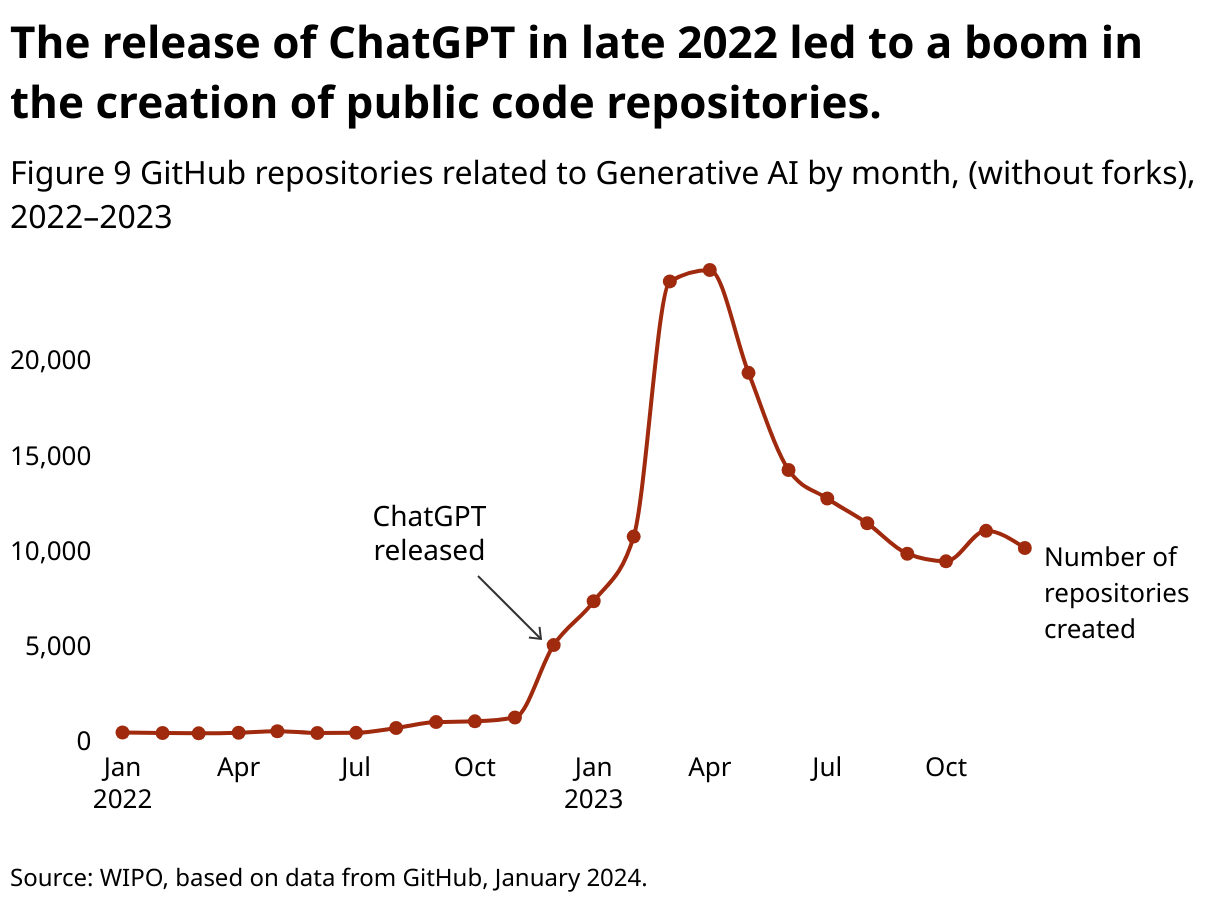
Using search terms similar to the ones described in the Appendix and the GitHub public API (GitHub 2023a), we present the recent public code repository creations by months with metadata related to GenAI terms in Figure 9. We observe a boom of creations at the time of the release of ChatGPT at the end of 2022, showing a massive recent interest in open-source developments in this area. The number of repository creations then goes down, as the activity might evolve naturally to improving and supporting these created repositories. These numbers show that we are still in the middle of a very recent wave of R&D interest in GenAI.
Most impactful software in generative AI
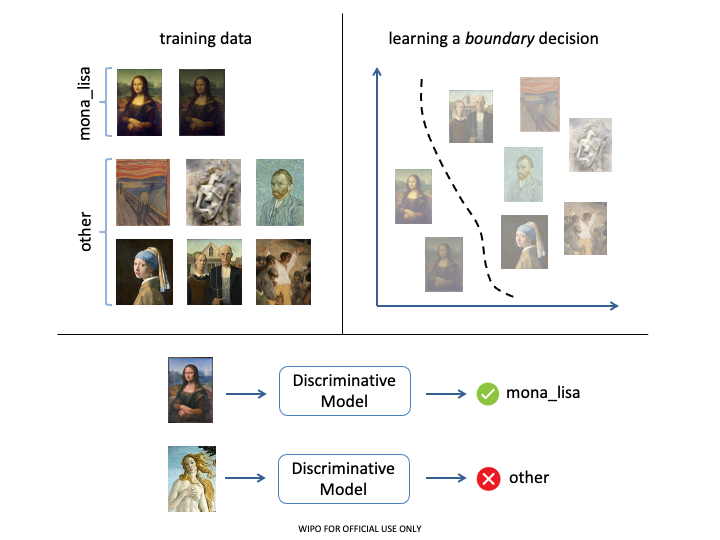
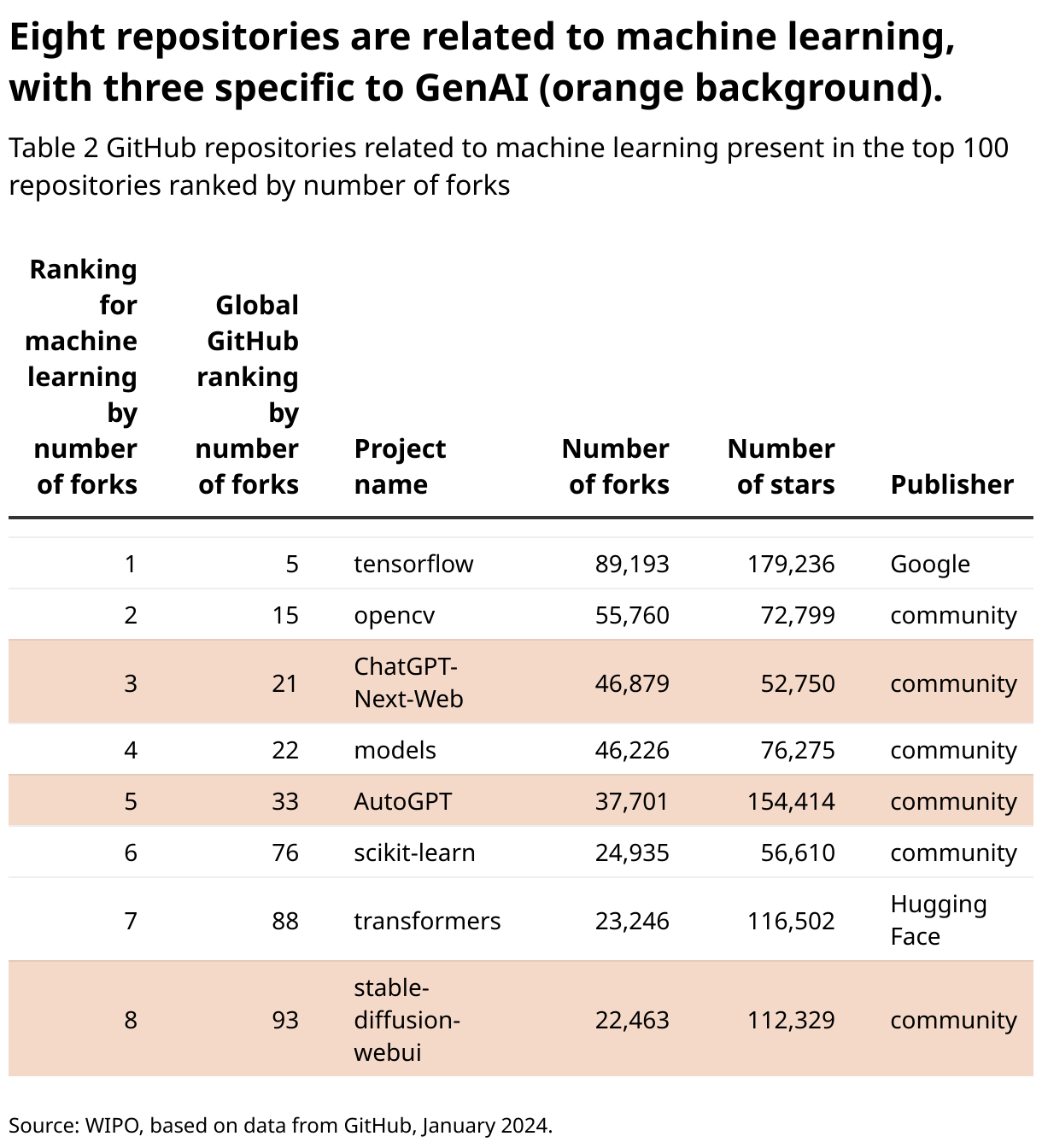
Table 2 presents the top Machine Learning GitHub repositories in terms of total number of forks ever produced (figures from December 6, 2023). A fork in open-source development is a copy of an existing repository for further extending or studying it. It can be viewed as a direct measure of interest and impact. Although all are relevant for GenAI, three out of eight are specific to GenAI (ChatGPT-Next-Web, AutoGPT and stable-diffusion-webui).
However, restricting our impact study to open-source software only would be incomplete. The software mentioned in scientific publications offer a more comprehensive picture of the actual impactful software in GenAI. We conducted a text mining analysis of the open access subset (34,183 PDF articles) of our GenAI corpus of scientific publications (a set of 75,870 scientific articles) and extracted 789,218 software mentions. The methodology is presented in Appendix A.1. Table 3 presents the 20 most cited GenAI software. OpenAI’s ChatGPT is the most cited software in terms of citing documents and is also intensively discussed with more than one hundred thousand mentions. If we ignore development frameworks and utilities, and focus only on software specific to GenAI (in bold in Table 3), around half of the highly cited software in the top 20 are proprietary and all from OpenAI (ChatGPT, GPT, Codex).