Global development
GenAI models can use many different types, or modes, of input and output data, such as text, image/video, voice and so on.
Among the different GenAI modes, most patent families belong to the image/video category. Between 2014 and 2023, there were almost 18,000 patent families in this mode, with more than 5,100 patent families in 2023 alone. Patent families that contain the processing of text and speech/sound/music are the third and fourth largest modes in terms of patent families, with almost 13,500 families each over the same period. So far, there are far fewer patent families in the remaining modes 3D image models, chemical molecules/genes/proteins and code/software (Figure 23).
However, similar to patents regarding GenAI models, a large number of patent families (around 14,300 patent family publications between 2014 and 2023) cannot be clearly assigned to any specific data type. In addition, some patent families are assigned to more than one mode as an increasing amount of GenAI models such as MLLMs are overcoming the limitation of only one type of data input and instead can access knowledge from multiple modalities.
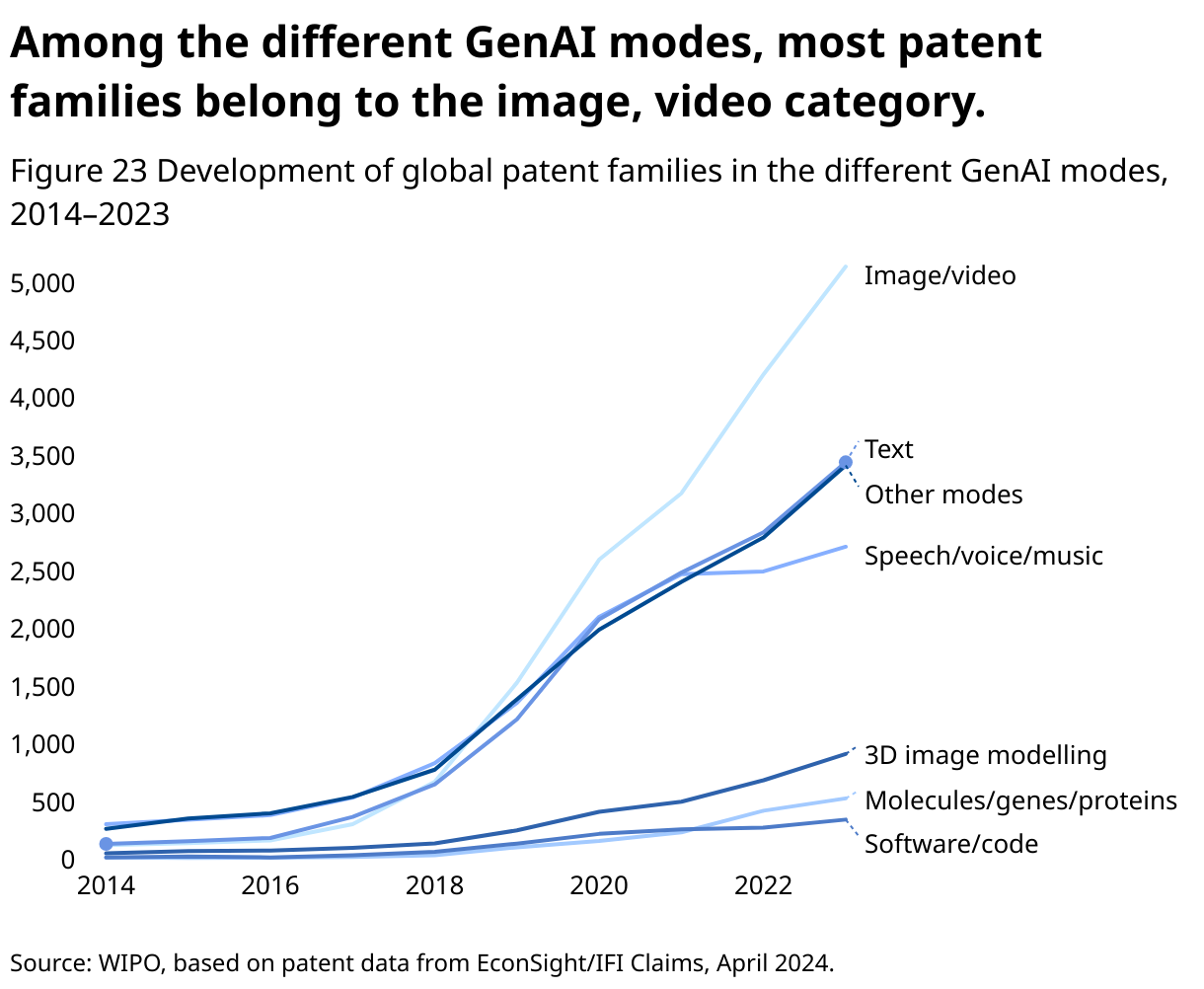
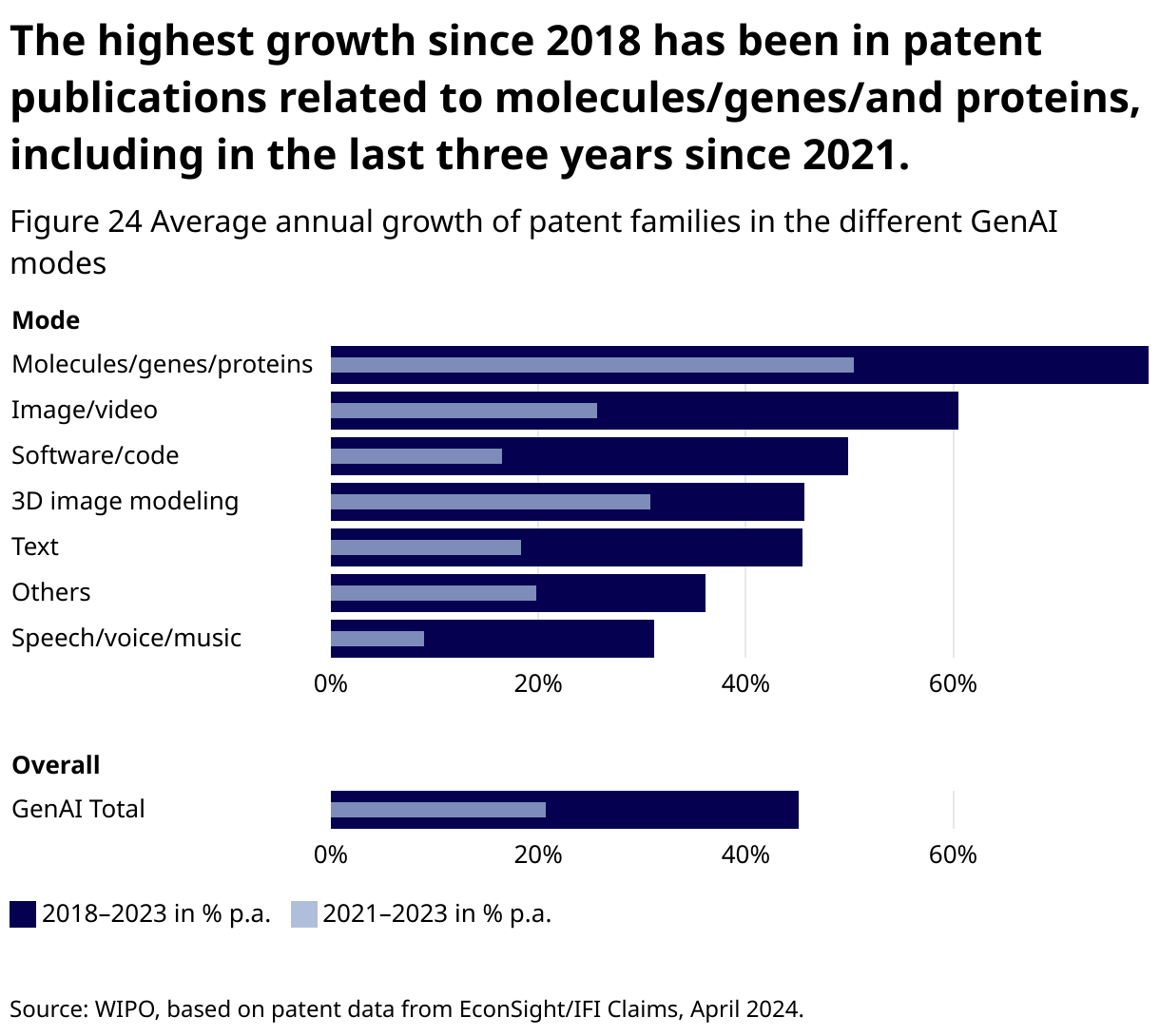
In terms of growth of patent families, image/video- and molecules/genes/proteins- based GenAI patent families increased the most over the last decade (an average annual growth rate of around 45% between 2014 and 2023). Molecules/genes/proteins GenAI patent families have also been the growth leaders in recent years. In contrast, the total number of GenAI patent families based on speech/sound/music data has increased only slightly since 2021 (Figure 24).
Top patent owners
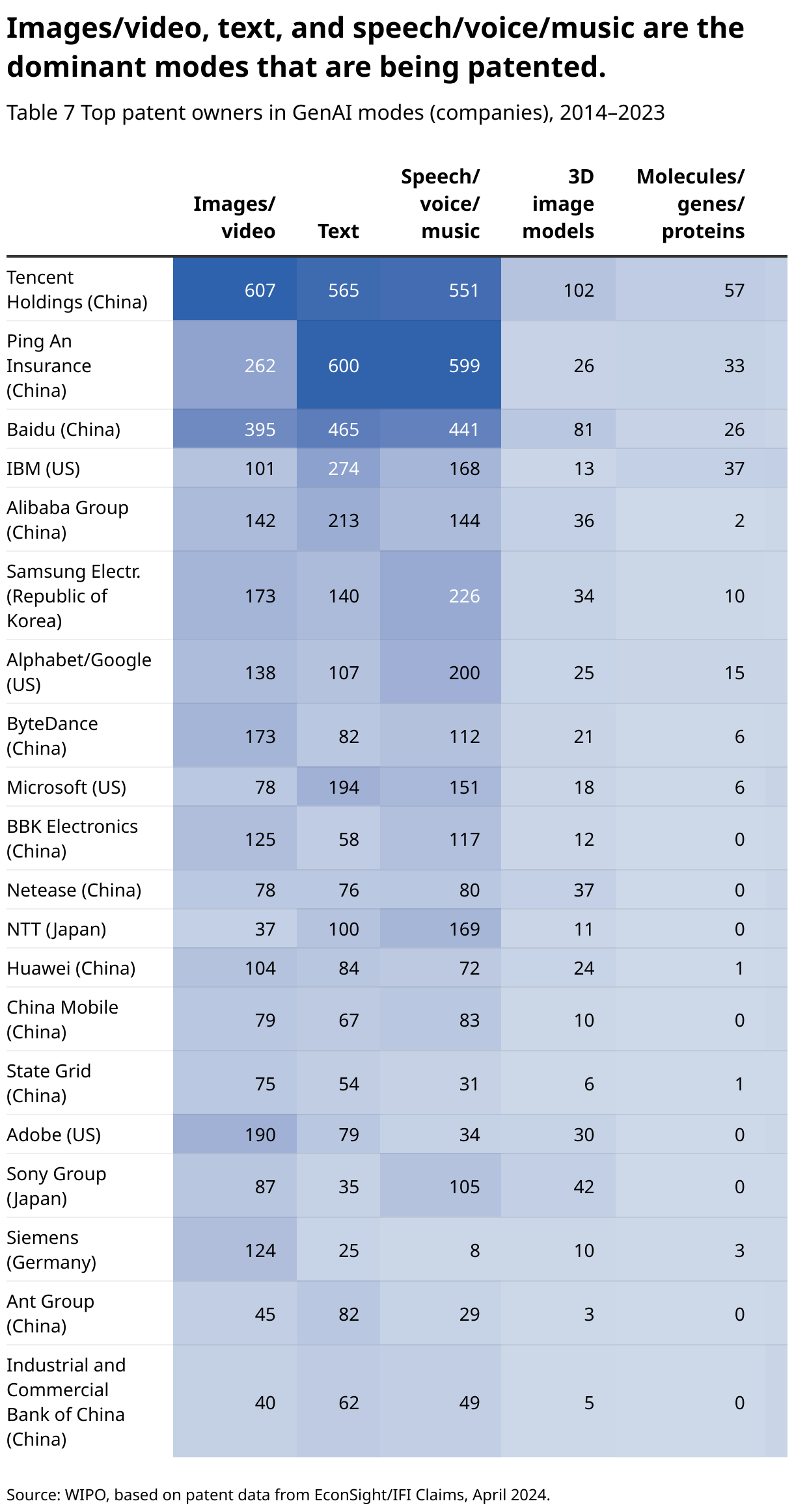
Tencent Holdings is the world leader in terms of published patent families in GenAI modes. The Chinese social media/gaming company is mainly active in GenAI research that processes the data types images/video, text, speech/voice/music as well as other modes. The Chinese companies Ping An Insurance and Baidu are close behind Tencent in terms of patent families and have a similar research pattern, focusing on the same modes (Table 7).
IBM ranks fourth and is the top US company in terms of GenAI patent families. IBM has many GenAI patents based on text processing. In addition, the company is the world leader in GenAI patent families in the software/code category. Samsung is ranked sixth and has a research focus on image/video, text or speech/voice/music based GenAI.
The top European company in terms of GenAI patent families is Siemens (18th), which has many patent families based on image/video data.
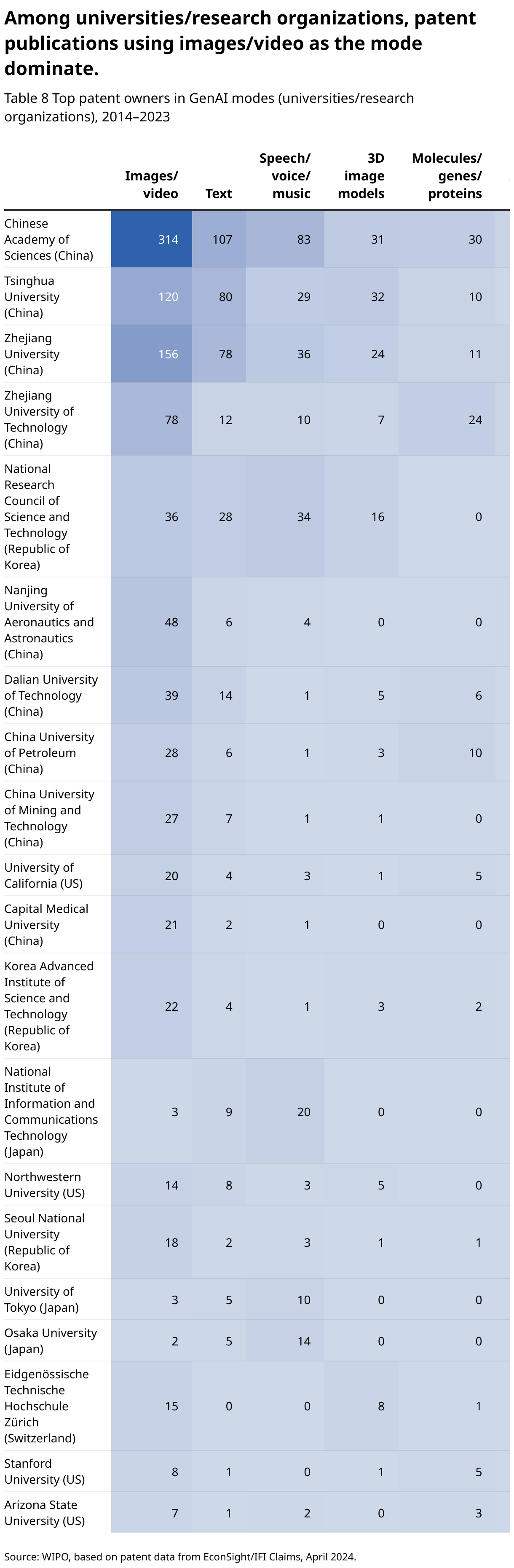
Looking at the top 20 research organizations in terms of GenAI patent families, the main research organizations have a focus on GenAI activities that process image/video data.
The Chinese Academy of Sciences is far ahead in terms of patent families based on image/video data, and it also holds the top position in most other GenAI modes. The only exceptions are in the 3D Image models category, where Tsinghua University leads the ranking with 32 patent families, and software/code-based GenAI patent families, where Zhejiang University holds the top spot with 10 patent families.
The number of GenAI patent families based on the use of text or speech/voice/music data is lower among most top universities and research organizations. This is in contrast to the research priorities of the top companies. Outliers are the National Research Council of Science and Technology from the Republic of Korea and the Japanese research organizations (National Institute of Information and Communications Technology, University of Tokyo, Osaka University), where the number of GenAI patent families based on speech/voice/music and text data is as high or higher than the number of patents based on image/video data.
Key locations of inventors
As with GenAI models, China is clearly the leading inventor location for all GenAI modes in terms of patent families that were published over the last decade (Table 9). In each category, more than 50% of all patent families were developed in China. Image/video-based GenAI is a key research area in China with almost 13,000 patent families since 2014. Text, other modes and speech/voice/music are other major GenAI research areas in China. However, the highest patent family growth rates in China were observed for patent families based on molecules/genes/proteins data (annual growth of 64% between 2021 and 2023).
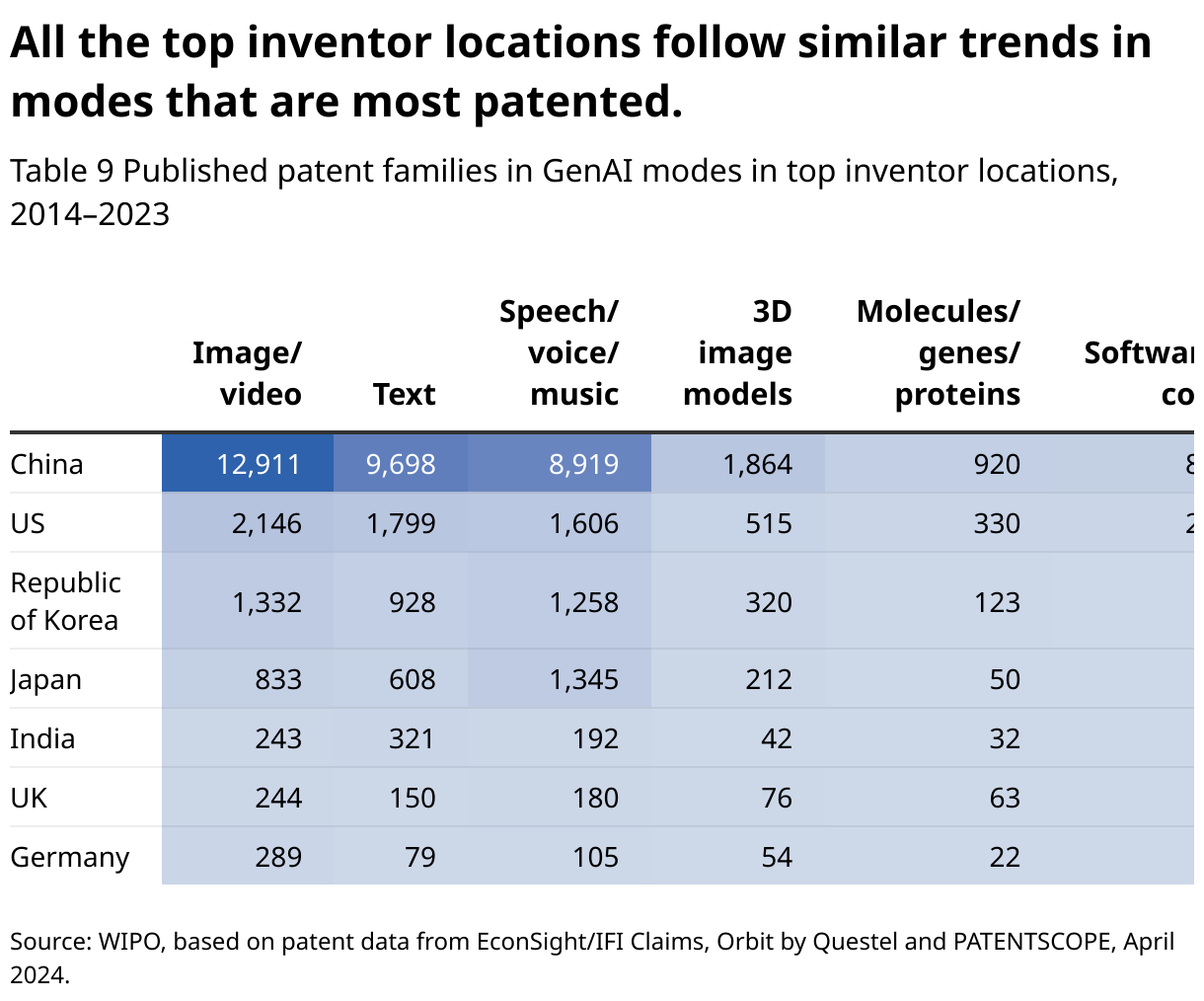
In the US, image/text-based GenAI patent families are the largest category (1,799 patent families since 2014), but the US world share is highest in the categories software/code GenAI and molecules/genes/proteins GenAI. In both categories, more than 20% of all patent families since 2014 were developed in the US.
In both Japan and the Republic of Korea, speech/voice/music is a very important GenAI mode in terms of patent families. However, patent growth rates differ significantly between the two Asian countries. While the growth of GenAI patent families in the Republic of Korea has been very dynamic across all modes in recent years, Japan's GenAI patent families peaked in 2020/2021 and have been declining since then.
Germany has a strong research focus on image, video-based GenAI.
In India, most GenAI patent families are based on text data.
Connection between GenAI models and GenAI modes
There is an interdependence between the use of a specific GenAI model for a certain GenAI application and the use of a specific GenAI mode. This is because some models work particularly well or depend on certain types of data. Our patent analysis (Figure 25) shows that:
Text is the most commonly used data type for LLMs.
Speech/voice/music is an important data type for GAN and VAE models.
GAN models are the most important model type for processing image/video data, 3D image models data and software/code data.
Molecules/genes/proteins data is mainly processed in GAN and VAE models.
The category other modes, i.e. data that does not fit into any of the other categories, plays an important role for VAE and GAN models.